The Modern Data Stack with dbt Framework
In today’s data-driven world, businesses rely on accurate and timely insights to make informed decisions and gain a competitive edge. However, the path from raw data to actionable insights can be challenging, requiring a robust data platform with automated transformation built-in to the pipeline, underpinned by data quality and security best practices. This is where dbt (data build tool) steps in, revolutionising the way data teams build scalable and reliable data pipelines to facilitate seamless deployments across multi-cloud environments.
What is a Modern Data Stack
The term modern data stack (MDS) refers to a set of technologies and tools that are commonly used together to enable organisations to collect, store, process, analyse, and visualise data in a modern and scalable fashion across cloud-based data platforms. The following diagram illustrates a sample set of tools & technologies that may exist within a typical modern data stack:
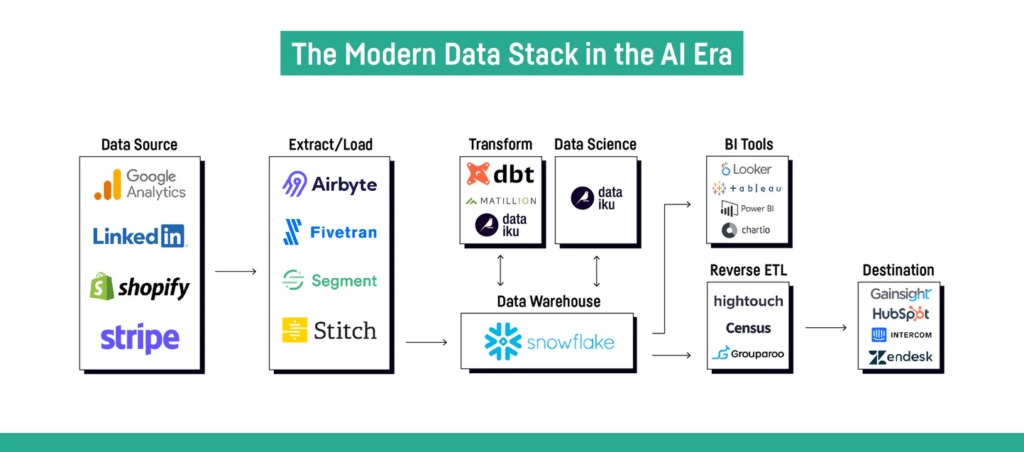
The modern data stack has included dbt as a core part of the transformation layer.
- Ingestion: Fivetran, Stitch
- Warehousing: Bigquery, Databricks, Redshift, Snowflake
- Transformation: dbt
- BI: Tableau, Power Bi, Looker
What is dbt (data build tool)?
dbt (i.e. data build tool) is an open-source data transformation & modelling tool to build, test and maintain data infrastructures for organisations. The tool was built with the intention of providing a standardised approach to data transformations using simple SQL queries and is also extendible to developing models using Python.
Advantages of dbt
It offers several advantages for data engineers, analysts, and data teams. Key advantages include:
- Modularity and Reusability: dbt promotes modular and reusable code by organising transformations into discrete units called models. These models can be easily reused across different projects, reducing redundancy and increasing efficiency in data transformations.
- Data Transformation Workflow: dbt provides a streamlined workflow for data transformations. It separates the process of transforming data from the process of loading data, allowing for incremental and iterative development. This modular approach makes it easier to understand, test, and maintain data transformations.
- Version Control: dbt integrates well with version control systems like Git, enabling versioning and collaboration on data transformation code. It allows teams to track changes, review code, and roll back to previous versions if needed, ensuring better code management and collaboration.
- Testing and Documentation: dbt includes built-in features for testing data quality and documenting transformations. Users can define tests to validate the correctness of transformed data, ensuring that data remains accurate and reliable. DBT also generates documentation automatically, making it easier to understand and communicate data transformations.
- Incremental Builds: dbt supports incremental builds, which means it can intelligently process only the data that has changed since the last run. This capability reduces the processing time and resource requirements for running transformations, making it more efficient for large datasets and frequent updates.
- Integration with Data Warehouse: dbt integrates seamlessly with popular cloud data warehouses like Snowflake, BigQuery, and Redshift. It leverages the capabilities and scalability of these warehouses, allowing users to take advantage of their processing power and storage for efficient data transformations.
- Collaboration and Governance: dbt provides a framework for collaboration and governance within data teams. It enables multiple team members to work on the same project simultaneously, with a clear separation of responsibilities. DBT also supports access control and permissions, ensuring that only authorised users can make changes to data transformations.
- Data Lineage and Impact Analysis: dbt allows users to track data lineage, which means understanding the origin and transformation history of data. This capability is valuable for auditing, compliance, and understanding the impact of changes on downstream reports and analytics.
Overall, dbt offers a powerful and flexible framework for data transformation and modeling, enabling data teams to streamline their workflows, improve code quality, and maintain scalable and reliable data pipelines in their data warehouses across multi-cloud environments.
Data Quality Checkpoints
Data Quality is an issue that involves a lot of components. There are lots of nuances, organisational bottlenecks, silos, and endless other reasons that make it a very challenging problem. Fortunately, dbt has a feature called dbt-checkpoint that can solve most of the issues.
With dbt-checkpoint, data teams are enabled to:
- Enforce mandatory documentation which implies that commits can’t be pushed unless tables or columns are documented
- Perform checks to ensure that certain column types have always the same prefix or suffix so they are easily discoverable
- Automatically run DBT unit and integration tests before merging a change into higher environment lanes. Integration tests can be very important as an observability tool, to identify unexpected logic changes at the source or data issues identified across the pipeline.
Data Profiling with PipeRider
Data reliability just got even more reliable with better dbt integration, data assertion recommendations, and reporting enhancements. PipeRider is an open-source data reliability toolkit that connects to existing dbt-based data pipelines and provides data profiling, data quality assertions, convenient HTML reports, and integration with popular data warehouses.
You can now initialise PipeRider inside your dbt project, this brings PipeRider’s profiling, assertions, and reporting features to your dbt models.
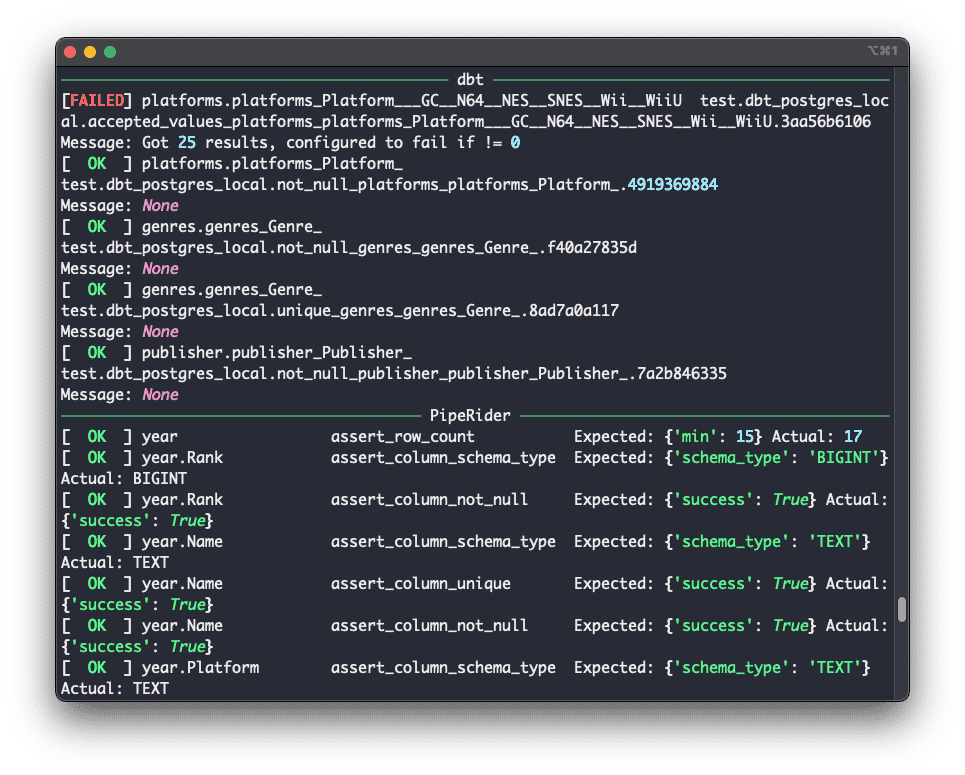
PipeRider will automatically detect your dbt project settings and treat your dbt models as if they were part of your PipeRider project. This includes –
- Profiling dbt models.
- Generating recommended assertions for dbt models.
- Testing dbt model data-profiles with PipeRider assertions.
- Including dbt test results in PipeRider reports.
How can TL Consulting help?
dbt (Data Build Tool) has revolutionised data transformation and modeling with its code-driven approach, modular SQL-based models, and focus on data quality. It enables data teams to efficiently build scalable pipelines, express complex transformations, and ensure data consistency through built-in testing. By embracing dbt, organisations can unleash the full potential of their data, make informed decisions, and gain a competitive edge in the data-driven landscape.
TL Consulting have strong experience implementing dbt as part of the modern data stack. We provide advisory and transformation services in the data analytics & engineering domain and can help your business design and implement production-ready data platforms across multi-cloud environments to align with your business needs and transformation goals.
