For organisations building Data Lakehouse platforms, an important consideration is defining a structured approach to designing data ingestion patterns, encompassing best practices for each data workload that is ingested into the Data Lakehouse environment. This is crucial for organisations looking to scale with big data analytics and enable more data consumers to perform efficient decision-making, with access to enriched data in real-time. In this article, we explore some of the best practices, key considerations and common pitfalls to avoid when defining the data ingestion patterns into the Data Lakehouse platform.
The Data Lakehouse Paradigm
The Data Lakehouse is a modern architecture that merges the expansive storage of a Data Lake with the structured data management of a Data Warehouse. The Data Lakehouse is the latest paradigm in Data Platform Architecture, combining the capabilities and benefits of the Data Warehouse and Data Lake into a flexible, comprehensive, and unified platform to serve many use cases including:
- Big Data and Streaming Analytics
- BI Reporting (including self-service analytics)
- Data Science and Machine Learning
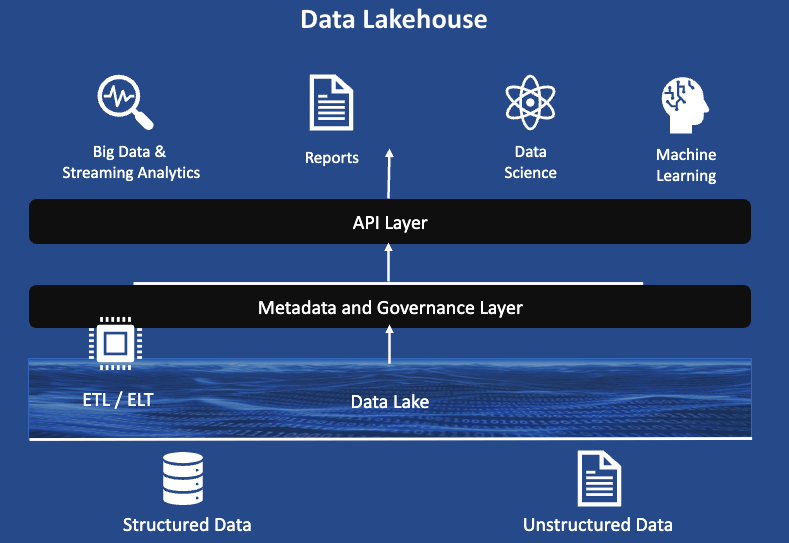
Defining the data ingestion design patterns for the Data Lakehouse requires defining a structured approach to collect and manage data workloads in the lakehouse while ensuring there are robust data quality and security controls in place as part of the data ingestion.
Key Considerations for Data Ingestion Patterns:
- Understanding the Data Sources – Effective data ingestion patterns ensure that there is a well-defined process in place to collect, organise and enrich data for big data analytics from various data sources (i.e., Relational Databases (OLTP systems), SaaS platforms, IoT devices, Flat-Files).
- This will also provide a standardised approach moving forward on how data transformations should take place, its important to define the right data formats (e.g., JSON, Parquet, Avro) for efficiency and performance.
- Another consideration is how structured vs. unstructured data will be stored to determine the implications for storage and analysis.
- Data Quality – A robust data ingestion process includes embedding data validation, cleaning, and transformation, which helps maintain data quality.
- By ensuring data accuracy, completeness, and consistency, organisations can make informed decisions based on reliable data.
- Scalability and Flexibility: Data ingestion frameworks are designed to handle large volumes of data from various sources. Scalable and flexible data ingestion processes allow organisations to adapt to changing data needs and accommodate future growth.
- This requires data platform teams to collectively ensure there are defined techniques for optimising data ingestion pipelines for scalability and performance.
- For example, this may include introducing partitioning and indexing strategies and managing workload and resource allocation in a multi-tenant environment.
- Batch vs Real-Time Processing: It’s important to choose the right ingestion strategy based on use cases and data characteristics.
- Timeliness of data is essential for making informed decisions and efficient data ingestion pipelines enable organisations to ingest and analyze data in real-time or near-real-time.
- Metadata Management – This is as an overarching layer to maintain a uniform catalog of all data attributes ingested into the lakehouse, ensuring there are correct controls in place that determine data lineage and quality, ensuring data continues to stay enriched over time, despite the potential of “data drift” based on upstream data source changes.
- Data Governance & Compliance – Data ingestion processes can incorporate data governance and data security practices, ensuring compliance with regulations and data security standards. This includes managing access controls, data privacy, and maintaining an audit trail of data activities. For example, implementing robust security measures to protect sensitive data and comply with regulatory requirements.
Common Pitfalls to Avoid
- Data Quality & Governance – Lack of Data Governance & Data Quality definition from the birth of the platform’s existence can lead to several impacts down the line, a data quality framework with specific controls & processes should be defined to govern the data and ensure it is enriched over time. Data platform engineers can consider running data quality checks within each data pipeline itself, or run these checks asynchronously for each data ingestion activity into the Data Lakehouse.
- Data Transformations – Underestimating the complexity of data transformations. Each data source will have its own problems around data quality, data cleansing & data types which need to be transformed in a structured and uniform way. Documenting these requirements using source-to-target mappings is essential before embarking on the transformation journey. For example, following a data ingestion pattern such as the Medallion Architecture (Bronze, Silver, Gold data transformation layers) is a structured way to approach data ingestion & processing, defining a standardised path to data enrichment for end-user consumption.
- Scalability & Optimisation – Overlooking the need for scalability and performance optimisation and thinking the cloud should be “scalable” to handle big data volumes is a common myth, it’s important to look at the data load from various angles, by looking at indexing, partitioning, job controlling as part of a Job Control framework etc.
- Metadata Management & Managing Schema Drift – Failing to plan for schema evolution over time will lead to many bottlenecks in the data pipelines, which may lead to downtime, and poor data quality as an output of the data processing activities.
Conclusion
In summary, the Data Lakehouse is a pathway to unlocking the full potential of your data, fostering innovation, and driving business growth. With the right components and strategic approach, your organisation can leverage Data Lakehouses to stay ahead of the curve, while maintaining a unified, cost-effective data platform deployed on your Cloud environment.
Designing correct data ingestion patterns will enable the Data Lakehouse platform to run efficient and scalable data pipelines to serve big data analytics use cases.
TL Consulting are a solutions partner with Microsoft in the Data & AI domain. We offer specialised and cost-effective data analytics & engineering services tailored to our customer’s needs to extract maximum business value. Our certified cloud platform & data engineering team are tool-agnostic and have high proficiency working with traditional and cloud-based data platforms.
Refer to our service capabilities to find out more.
