When building Machine Learning (ML) models, we often encounter unorganised and chaotic data. In order to transform this data into explainable features, we rely on the process of feature engineering.
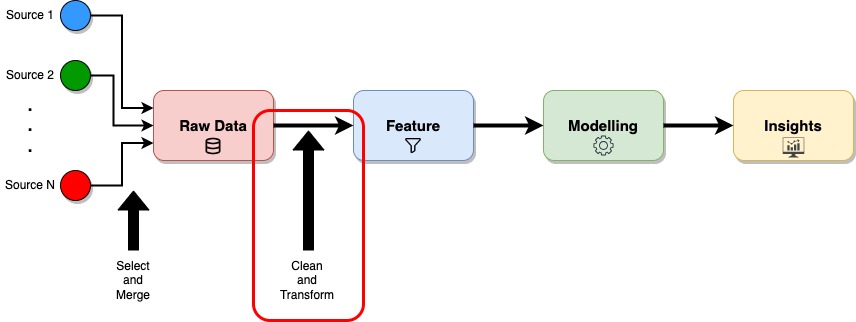
Feature engineering plays a crucial role in the Cross Industry Standard Process for Data Mining (CRISP-DM). It is an integral part of the Data Preparation Step, responsible for organising the data effectively before it is ready for modeling. The diagram below illustrates the significance of feature engineering (FE) in the data mining process.
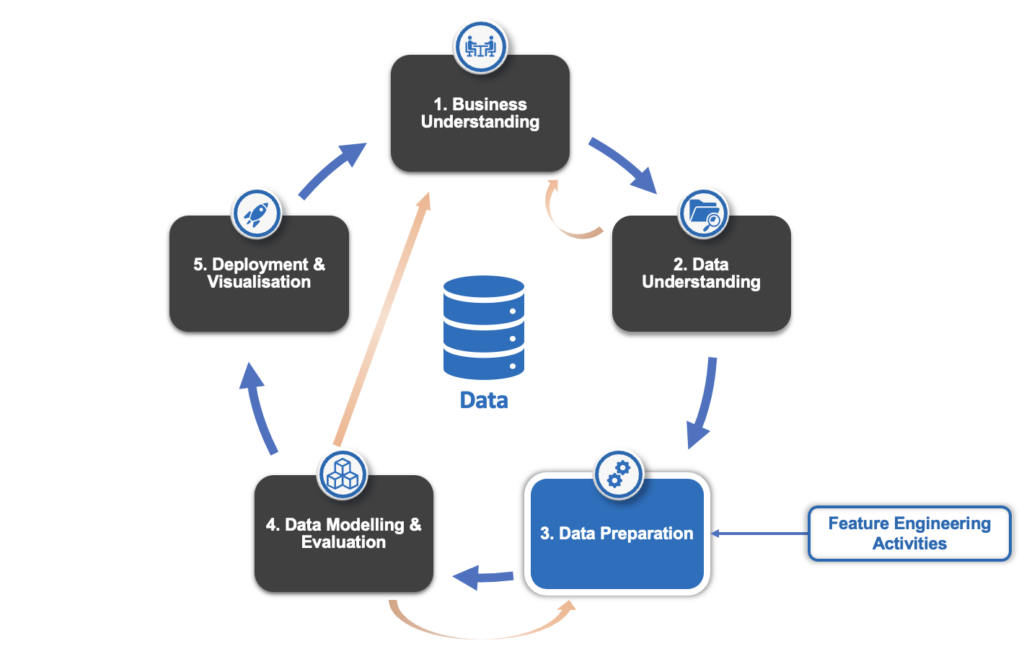
What is Feature Engineering?
Feature Engineering (FE) is the process of extracting and organising important information from raw data in such a way that it fits the machine learning (ML) model.
Why is Feature Engineering Important?
Feature Engineering (FE) has many benefits to offer in the CRISP-DM process. They include:
- Provides more flexibility and less complexity in models
- Faster data processing
- Understanding of models becomes easier
- Better understanding of the problem and questions to be answered
Feature Engineering Techniques for Machine Learning (ML)
Below is a list of feature engineering techniques and we will summarise each:
- Imputation:
- Handling Outliers
- Log Transformation
- One-Hot Encoding
- Scaling
1. Imputation
Missing values is one of the most typical problems when it comes to data preparation. Human errors and dataflow interruptions are some of the major contributors to this problem. Moreover, missing values can detrimentally impact the performance of the ML models.
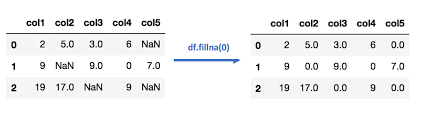
Imputation is frequently employed in healthcare research, such as when dealing with patient records that may have missing values for certain medical measurements. By imputing the missing data using methods like mean imputation or regression imputation, researchers can ensure that a complete dataset is available for analysis, allowing for more accurate assessments and predictions.
2. Handling Outliers
Handling Outliers within datasets is an important technique with the purpose of creating an accurate representation of the data. This step must be completed prior to the model training step. There are various methods of handling outliers that include removal, replacing values, capping, and discretization. These methods will be discussed in detail in future blogs.
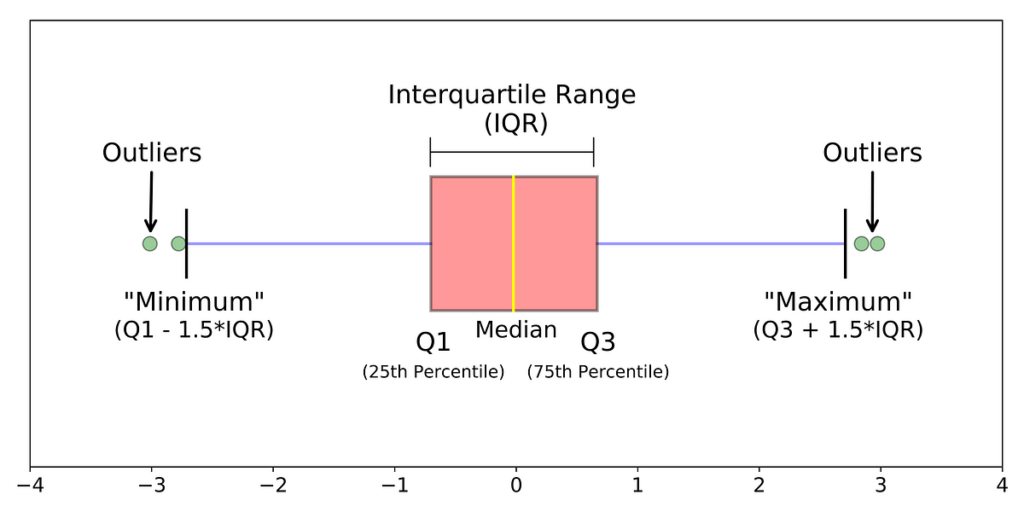
Handling outliers is essential in financial analysis, for instance, when examining stock market data. By detecting and appropriately treating outliers using techniques like Winsorization or trimming, analysts can ensure that extreme values do not unduly influence statistical measures, leading to more robust and reliable insights and decision-making.
3. Log Transformation
Log Transformation is one of the most prevalent methods used by data professionals. The technique transforms a skewed distribution of data into normally distributed or slightly skewed data. Therefore, making the data approximate for normal applications is required for different kinds of data analysis.
Log transformation is commonly applied in skewed data distributions, such as when dealing with income or population data. By taking the logarithm of the values, the skewed distribution can be transformed into a more symmetric shape, facilitating more accurate modeling, analysis, and interpretation of the data.
4. One Hot Encoding
One-Hot Encoding is a technique of preprocessing categorical variables into ML models. The encoding transforms a category variable into a binary feature for each category. It typically assigns a value of ‘1’ to the binary feature it corresponds to and all other binary features are set to ‘0’.
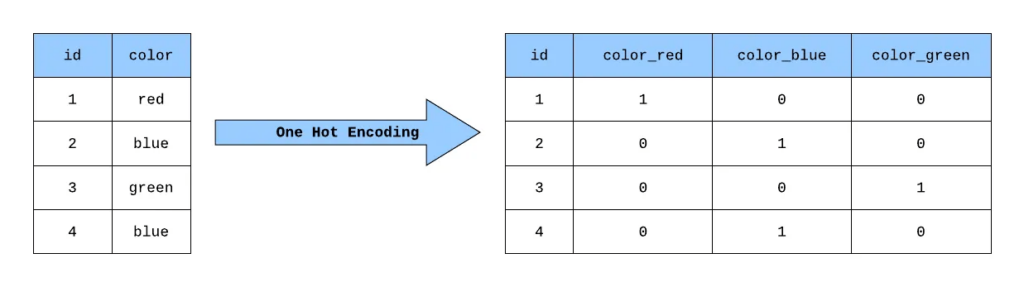
One-hot encoding is widely used in categorical data processing, such as in natural language processing tasks like sentiment analysis. By converting categorical variables into binary vectors, each representing a unique category, one-hot encoding enables machine learning algorithms to effectively interpret and utilize categorical data, facilitating accurate classification and prediction tasks.
5. Scaling
Feature scaling is one of the hardest problems in data science to get right. However, it is not a mandatory step for all machine learning models. It is only applicable to distance-based machine learning models. The training model process requires data with a known set of features that need to be scaled up or down where it is deemed appropriate. The outcome of the scaling operation transforms continuous data to be similar in terms of range. The most popular techniques for scaling are Normalization and Standardisation, which will be discussed in detail in future blogs.
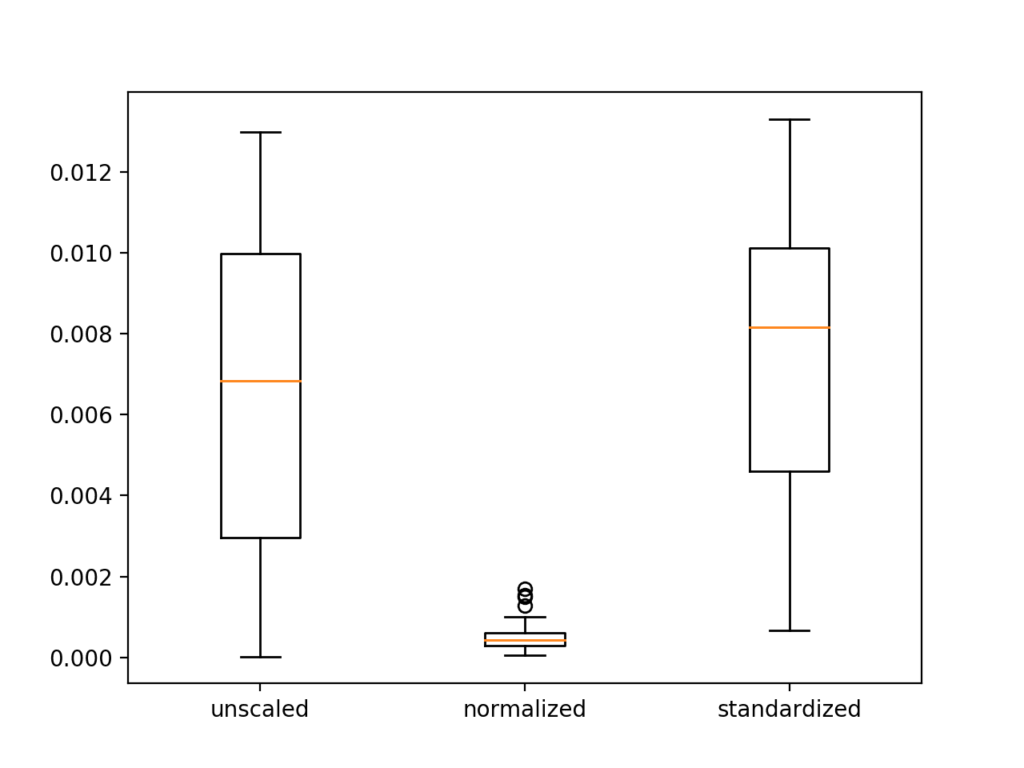
Scaling is often used in image processing, such as when resizing images for a computer vision task. Scaling the images to a consistent size, regardless of their original dimensions ensures that the images can be properly processed and analysed, allowing for fair comparisons and accurate feature extraction in tasks like object recognition or image classification.
Feature Engineering Tools
There are a set of feature engineering tools that are popular in the market in terms of the capabilities it provides. We have listed a few of our recommendations:
- FeatureTools
- AutoFeat
- TsFresh
- OneBM
- ExploreKit
Conclusion
In summary, Feature Engineering is a crucial step in the CRISP-DM process before we even think about training our machine learning models. One of the core advantages include the training time of models is reduced significantly. As a result, it allows for a drastic reduction of cost in terms of utilisation of expensive computing resources. In this article, we learned a number of feature engineering techniques and tools that are used in the industry.
Here at TL Consulting, our data consultants are experts at using feature engineering techniques to build highly accurate machine learning models, enabling us to deliver high-quality outcomes to support our customer’s data analytics needs.
TL Consulting provides advisory and transformation services in the data analytics & engineering domain and has helped many organisations achieve their digital transformation goals.
Visit TL Consulting’s data-engineering page to learn more about our service capabilities and send us an enquiry if you’d like to learn more about how our dedicated consultants can help you.


